|
Ryo Takizawa I am a first-year phD student at the University of Tokyo. I am a member of Intelligent Systems and Informatics Laboratory (2023-). I received my Master’s degree from the Graduate School of Information Science and Technology at the University of Tokyo (2023-2025) and my Bachelor’s degree from the Department of Precision Engineering, the University of Tokyo (2019-2023). My main research focus is to make robots more intelligent. Rather than merely focusing on factory automation technology, I aim to develop methodologies that enable robots to adaptively expand their capabilities in real-world environments, much like humans do. With this objective, both my master's research and my doctoral research primarily focus on robotic object manipulation. |

|
News[August 19, 2025] My paper was accepted for RA-L! [June 20, 2025] My first paper was accepted for IROS 2025! [Feb 9, 2025] Create this webpage. |
Publications |
|
|
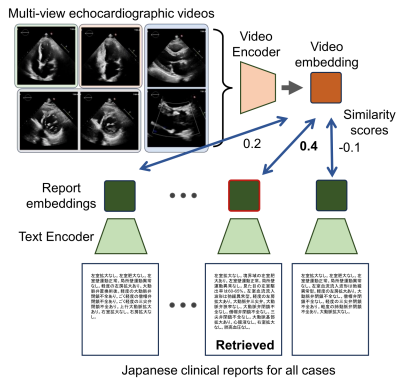
Video CLIP Model for Multi-View Echocardiography Interpretation
Ryo Takizawa*, Satoshi Kodera, Tempei Kabayama, Ryo Matsuoka, Yuta Ando, Yuto Nakamura, Haruki Settai, Norihiko Takeda NeurIPS Workshop TS4H, 2025 arXiv / code We proposed multi-view echocardiography interpretation using video CLIP model which takes five different views and full video sequences as input. The model is trained on pairs of echocardiographic videos and clinical reports from 60,747 cases. Our experiments demonstrate that our CLIP model benefits from both video inputs and multi-view data. |
|
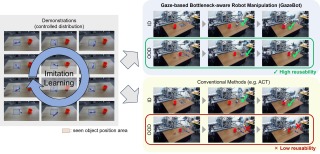
Enhancing Reusability of Learned Skills for Robot Manipulation via Gaze
Information and
Motion Bottlenecks
Ryo Takizawa*, Izumi Karino, Koki Nakagawa, Yoshiyuki Ohmura, Yasuo Kuniyoshi IEEE RA-L, 2025 website / arXiv / code GazeBot enables high reusability of the learned motions even when the object positions and end-effector poses differ from those in the provided demonstrations. GazeBot achieves high generalization performance compared with state-of-the-art imitation learning methods without sacrificing its dexterity and reactivity, and its training process is entirely data-driven once a demonstration dataset with gaze data is provided. |
|
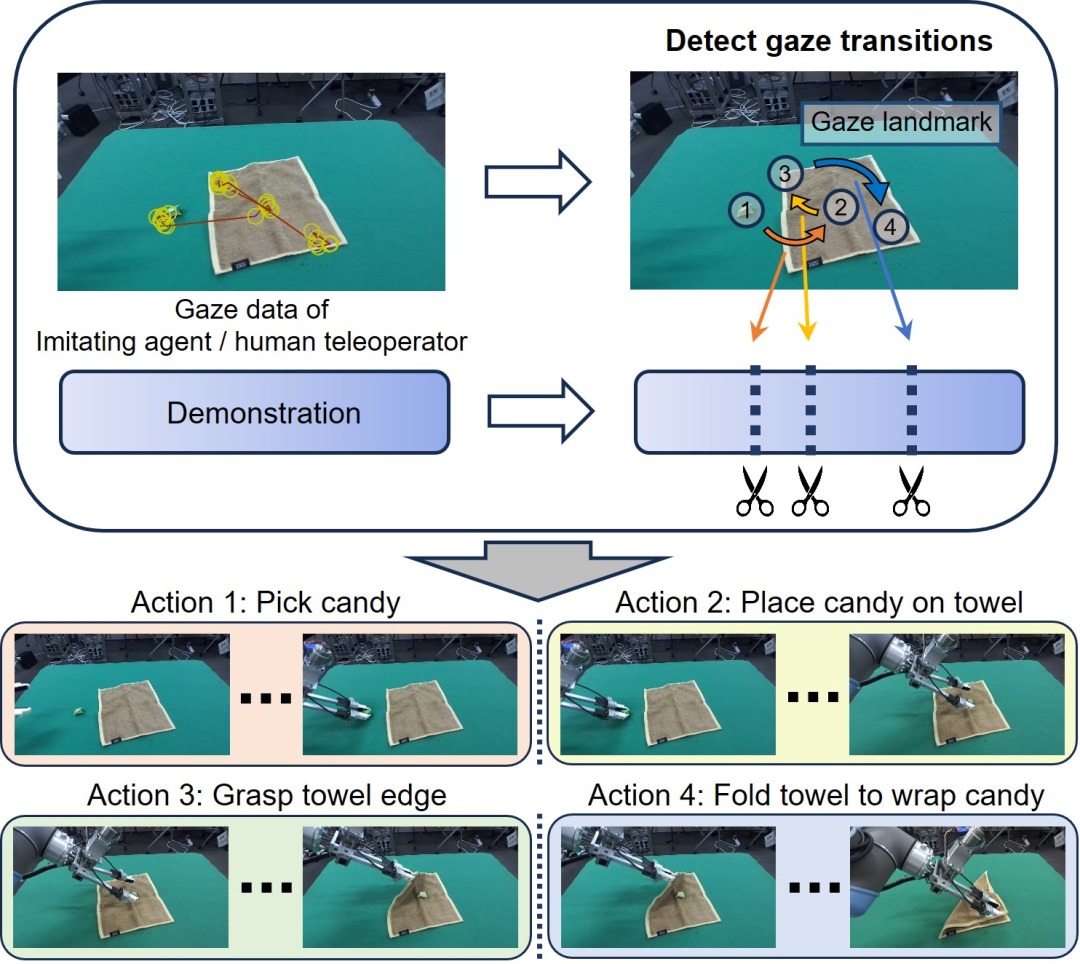
Gaze-Guided Task Decomposition for Imitation Learning in Robotic
Manipulation
Ryo Takizawa*, Yoshiyuki Ohmura, Yasuo Kuniyoshi IROS, 2025 arXiv / code A simple yet robust task decomposition method based on gaze transitions. This method leverages teleoperation, a common modality in robotic manipulation for collecting demonstrations, in which a human operator's gaze is measured and used for task decomposition. Notably, our method achieves consistent task decomposition across all demonstrations for each task, which is desirable in contexts such as deep learning. |
Other Work |
|

|
Tong Simulator
simulator GitHub / API GitHub A simulator for the ISI Lab dual-arm robot "Tong System". |
|
|